There are times I really enjoy using Ruby on Rails. Recently, Fishpond started 403’ing http requests for cover images if the referrer isn’t fishpond.com.au. Sites do this so that other sites don’t steal their bandwidth. Really, Booko should be downloading the images and serving them itself (It’s on the todo list BTW). Since Booko had been using Fishpond image URLs to display covers, you may have noticed a bunch of missing cover images – some of them are caused by Fishpond’s new (completely reasonable) policy.
So I’ve updated the code so I don’t link to Fishpond images, but now I need to go through every product Booko’s ever seen and update those with a Fishpond image URL. This is laughably easy with ruby on rails. Just fire up the console and run this:
Product.find_each do |p|
if p.image_url =~ /fishpond/
puts "updating details for #{p.gtin}"
p.image_url=nil
p.get_detail
p.save
end
end
The Rails console gives you access to all the data and models of your application – and this code, just pasted in, will find links to all Fishpond images, find a replacement image, or set it to nil. Point of interest – Booko has 396,456 products in its database. Iterating with Product.all.each would load every product into memory before hitting the each – that would probably never return. On the other hand Product.find_each loads records in batches of 1000 by default. Pretty cool.
While developing new features or bug fixes Booko, I usually work in branches. This makes keeping things separate easy, and means I can easily keep the current production version clean and easy to find. But when changing branches I often have to restart the rails server and the price grabber to pickup any changes. For example, if I’m adding a new shop in a branch, when I switch branches I want the price grabber to restart.
Turns out git makes this super easy. You just create a shell script: .git/hooks/post-checkout
That script gets called after checkout. So, mine is pretty simple:
The excellent people at Phusion have released a 1.8.7 based version of their fantastic Ruby Enterprise Edition. I’ve just updated to it and Booko sure feels snappier. I’ve also upgraded to the latest mod_rails (aka, phusion-passenger) so we’re all up-to-date on my medium-ticket sysadmin work.
I love Google – they send me stacks of traffic and make sites like Booko reach a far greater audience than I could effect on my own. Recently, however, Google’s taken a bigger interest in Booko than usual. These kinds of numbers are no problem in general – the webserver and database are easily capable of handling the load.
The problem for Booko, when Google comes calling, is that they request pages for specific books such as:
When this request comes in, Booko will check to see how old the prices are – if they’re more than 24 hours old, Booko will attempt to update the prices. Booko used to load the prices into the browser via AJAX – so, as far as I can tell, Google wasn’t even seeing the prices. Further, Booko has a queuing system in place for requests to look up prices, so when Google requests pages, this adds a book to the queue of books to be looked up. Google views books faster than Booko can grab the prices, so we end up with 100’s of books scheduled for lookup, frustrating normal Booko users who see the problem as a page full of spinning wheels – wondering why Booko isn’t giving them prices. Meanwhile, the price grabbers are hammering through hundreds of requests from Google, in turn, hammering all the sites Booko indexes. So, what to do?
Well, the first thing I did was drop Google’s traffic. I hate the idea of doing this – but really Booko needs to be available to people to use and being indexed by Google won’t help if you can’t actually use it. So to the iptables command we go:
iptables -I INPUT -s 66.249.71.108 -j DROP
iptables -I INPUT -s 66.249.71.130 -j DROP
These commands will drop all Google traffic.
The next step was to go to sign up for Google Webmaster Tools and reduce the page crawl rate.
Once I’d dialled back Google’s crawl rate, I dropped the iptables rules:
iptables -F
To make Booko more Google friendly, the first code change was to have book pages rendered immediately with the available pricing (provided it’s complete) and have updates to that pricing delivered via AJAX. Google now gets to see the entire page and should (hopefully) provide better indexing.
The second change was to create a second queue for price updates – the bulk queue. The price grabbers will first check for regular price update requests – meaning people will get their prices first. Requests by bulk users, such as Google, Yahoo & Bing, will be added to the bulk queue and looked up when there are no normal requests. In addition, I can restrict the number of price grabbers which will service the bulk queue.
This work has now opened up a new idea I’ve been thinking about – pre-emptively grab the prices of the previous day or week’s most popular titles. The idea would be to add these popular titles to the bulk queue during the quiet time between 03:00 and 06:00. That would mean that when people viewed the title later that day, they’d be fresh.
I’ve just pushed these changes into the Booko site and with some luck, Google & Co will be happier, Booko users will be happier and I should be able to build new features with this ground work laid. Nice for a Sunday evening’s work.
It’s been great fun writing Booko in Ruby on Rails for lots of reasons, and the ORM module – ActiveRecord, is a big part of what makes it enjoyable. I know that ORMs exist in plenty of other languages, but RoR was my first exposure to it and it makes writing database backed applications much less tedious. But, as with all abstractions though, looking under the covers can help you solve problems and improve performance.
Booko has a “Most Viewed” section, which finds the products which have been viewed the most over the last 7 days. It does this by having a model called “View” which, as you might guess, records product views. The Product class asks the View class for the top 10 viewed products:
class Product < ActiveRecord::Base
...
def self.get_popular(period = 7.days.ago, count = 10 )
View.popular(period).collect {|v| v.product }.reverse.slice(0...count)
end
..
end
This all worked ok – but once the number of products being viewed started to grow into the 1000’s, this started taking longer and longer to generate the data for the view. At last count, it was running into the 50 second mark – way, way too long. The result of the calculation is cached for 30 minutes but that means that every 30 minutes, some poor user had to wait ~ 50seconds for the “Most Viewed” section to render. Time for a rethink.
There’s one obvious problem with the above method – all products viewed in the last 7 days are returned from the named_scope and instantiated and then count (by default, 10 ) number of Products are sliced off the result and are then displayed. Time to update the named scope so that it returns only the required number of products, and as a bonus, return them in the right order removing the need for the reverse method call.
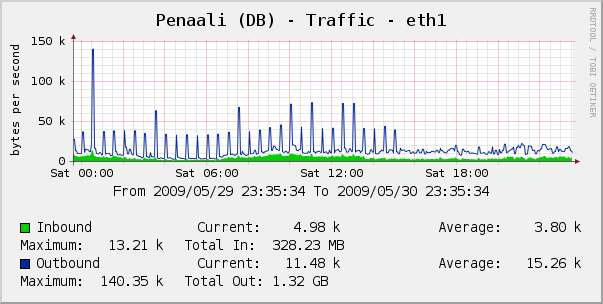
Updating the named_scope to return the required number of Products (in the right order), reduced the time from 56 seconds, to 6. In fact, subsequent calls returned in ~2 second mark no doubt due to some caching at the database side. Below is the graph showing network traffic to the database host. You can see periodic spikes, every 30 minutes, as the query ran and the database is hit for the 1000’s of Products to be instantiated. After the update, just after 15:00, the traffic becomes much steadier.
database traffic
Moving that logic from the Ruby side to the database side resulted in a pretty substantial performance improvement.
If Booko looks up 1000 book prices in 1 day, it will be making 1000 queries to 33 online stores. How much quota could be saved by using HTTP compression? Picking a page such as the one below from Book Depository, I did a quick test. First, I fired up the Booko console and set the URL, grab the page and see how big it is::
That’s around 7 KB, which is about 20% of the non-compressed version.
So, 1000 books from 33 shops is 33,000 requests per day. If they were all 37KB (of course they aren’t but let’s play along) we get around 1,200 MB of data or 1.2 GB. If they’re were all compressed down to 7KB, that would come to around 235 MB. Using compression means there’s a trade off – higher CPU utilisation. However, the price grabbers spend most of their time waiting for data to be transmitted – any reduction in this time should yield faster results with significantly lower bandwidth usage.
No prizes for guessing the next feature I’m working on adding to Booko 😉
Update: Thanks to Anish for fixing my overly pessimistic calculation that 1,200 MB == 1.2 TB.
After a false start on Thursday morning, Booko is now distributed across multiple servers: the Web server, the Database server and the Price server (well, price grabber). Having these components separated out will make expanding Booko much easier than when it was deployed to a single host.
Once the web server load grows higher than a single host can handle, the next step will be to load balance the web servers – with nginx or Varnish or HAProxy or maybe even Apache.
I took the opportunity of some downtime to upgrade to the latest versions of Ruby Enterprise Edition and Passenger (mod_rails) from the awesome guys at Phusion.
All this means that Booko should now be a touch snappier. Enjoy!