Hey everyone – just a quick note to say I’ve added Borders to Booko. Enjoy!
All posts by Dan Milne
Sysadmin Triage
Wrote an article on Sysadmin Triage over at my personal blog for anyone interested in that type of thing.
A gaggle of updates
Just pushed out some more updates to Booko:
- Moved Booko’s gem dependencies into environment.rb. Should have done this ages ago. (Read about it here)
- Started moving from Hpricot to Nokogiri. Hpricot was awesome, but it’s been choking on some websites and crashing the price grabbers.
- Started moving from timeout.rb to SystemTimer because I would like my timeouts to, you know, timeout. Sheesh.
- Updated the memcache-client to use SystemTimer for the same reason.
- Added more testing
Moving processing to the Database
It’s been great fun writing Booko in Ruby on Rails for lots of reasons, and the ORM module – ActiveRecord, is a big part of what makes it enjoyable. I know that ORMs exist in plenty of other languages, but RoR was my first exposure to it and it makes writing database backed applications much less tedious. But, as with all abstractions though, looking under the covers can help you solve problems and improve performance.
Booko has a “Most Viewed” section, which finds the products which have been viewed the most over the last 7 days. It does this by having a model called “View” which, as you might guess, records product views. The Product class asks the View class for the top 10 viewed products:
class Product < ActiveRecord::Base
...
def self.get_popular(period = 7.days.ago, count = 10 )
View.popular(period).collect {|v| v.product }.reverse.slice(0...count)
end
..
end
The View makes use of named scopes:
class View < ActiveRecord::Base
....
named_scope :popular, lambda { |time_ago| { :group => 'product_id',
:conditions => ['created_on > ?', time_ago],
:include => :product,
:order => 'count(*)' } }
...
end
class Product < ActiveRecord::Base
...
def self.get_popular(period = 7.days.ago, count = 10 )
View.popular(period).collect {|v| v.product }.reverse.slice(0...count)
end
...
end
The View makes use of named scopes:
class View < ActiveRecord::Base
....
named_scope :popular, lambda { |time_ago| { :group => 'product_id',
:conditions => ['created_on > ?', time_ago],
:include => :product,
:order => 'count(*)' } }
...
end
This all worked ok – but once the number of products being viewed started to grow into the 1000’s, this started taking longer and longer to generate the data for the view. At last count, it was running into the 50 second mark – way, way too long. The result of the calculation is cached for 30 minutes but that means that every 30 minutes, some poor user had to wait ~ 50seconds for the “Most Viewed” section to render. Time for a rethink.
There’s one obvious problem with the above method – all products viewed in the last 7 days are returned from the named_scope and instantiated and then count (by default, 10 ) number of Products are sliced off the result and are then displayed. Time to update the named scope so that it returns only the required number of products, and as a bonus, return them in the right order removing the need for the reverse method call.
class Product < ActiveRecord::Base
...
def self.get_popular(period = 7.days.ago, count = 10 )
View.popular(period, count).collect {|v| v.product }
end
...
end
class View < ActiveRecord::Base
....
named_scope :popular, lambda { |time_ago, freq| { :group => 'product_id',
:conditions => ['created_on > ?', time_ago],
:include => :product,
:order => 'count(*) desc',
:limit => freq } }
...
end
Updating the named_scope to return the required number of Products (in the right order), reduced the time from 56 seconds, to 6. In fact, subsequent calls returned in ~2 second mark no doubt due to some caching at the database side. Below is the graph showing network traffic to the database host. You can see periodic spikes, every 30 minutes, as the query ran and the database is hit for the 1000’s of Products to be instantiated. After the update, just after 15:00, the traffic becomes much steadier.
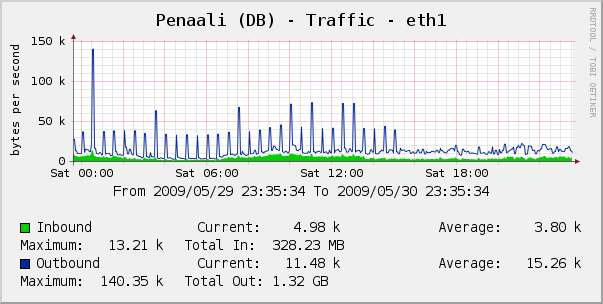
Moving that logic from the Ruby side to the database side resulted in a pretty substantial performance improvement.
To compress?
If Booko looks up 1000 book prices in 1 day, it will be making 1000 queries to 33 online stores. How much quota could be saved by using HTTP compression? Picking a page such as the one below from Book Depository, I did a quick test. First, I fired up the Booko console and set the URL, grab the page and see how big it is::
>>url="http://www.bookdepository.co.uk/browse/book/isbn/9780141014593" >>open(url).length => 38122
That’s the length in characters, which is ~ 37 KB. Let’s turn on compression and see if it makes much difference:
>> open(url, "Accept-encoding" => "gzip;q=1.0,deflate;q=0.6,identity;q=0.3").length
=> 7472
That’s around 7 KB, which is about 20% of the non-compressed version.
So, 1000 books from 33 shops is 33,000 requests per day. If they were all 37KB (of course they aren’t but let’s play along) we get around 1,200 MB of data or 1.2 GB. If they’re were all compressed down to 7KB, that would come to around 235 MB. Using compression means there’s a trade off – higher CPU utilisation. However, the price grabbers spend most of their time waiting for data to be transmitted – any reduction in this time should yield faster results with significantly lower bandwidth usage.
No prizes for guessing the next feature I’m working on adding to Booko 😉
Update: Thanks to Anish for fixing my overly pessimistic calculation that 1,200 MB == 1.2 TB.
New hardwarez for Booko
After a false start on Thursday morning, Booko is now distributed across multiple servers: the Web server, the Database server and the Price server (well, price grabber). Having these components separated out will make expanding Booko much easier than when it was deployed to a single host.
Once the web server load grows higher than a single host can handle, the next step will be to load balance the web servers – with nginx or Varnish or HAProxy or maybe even Apache.
I took the opportunity of some downtime to upgrade to the latest versions of Ruby Enterprise Edition and Passenger (mod_rails) from the awesome guys at Phusion.
All this means that Booko should now be a touch snappier. Enjoy!
Author searches
Thanks to Buck for recommending the latest feature for Booko. Clicking on the author name now searches Booko for that author. Pretty logical idea really – works quite well.
New Engine for Booko
Over the last few months traffic to Booko has been steadily growing – the kind of growth I like. Steady growth allows you to plan how to make things go faster without having to make crazy, on the fly tweaks to help things along (or stop them from falling over). I’ve tried to design Booko to make it scale up easily – it’s basically split into two main components: the website is the front end, and the price grabber which is a separate bit of code, sits quietly in the background looking up prices. They talk to each other via the database – the website says “Hey Price Grabber, get me some prices for ISBN 123” (it does this by updating the database) , and the price grabber dutifully goes and grabs the prices and stores them in the database when it’s done, which the website then displays.
The idea was that I’d make the price grabber threaded, so that it could look up multiple books at once. Turns out, Ruby may not have been the best choice for a highly threaded, I/O based bit of code. Well, at least not Ruby 1.8. It’s interesting to see that JRuby may in fact be the best way to run this type of code. Ruby 1.8’s threading model blocks on I/O – not great for my price grabber. The solution is pretty easy though – just run multiple price grabbers – which is what I’ve done. So, Booko can now have as many price grabbers as needed. They talk politely to each other via the database (so that, for example, two pricers don’t look up prices for the same book.)
This has been lightly tested but should be pretty stable – let me know if you have any problems getting prices.
Bugs, Outages and a new shop.
It’s been a long night – the generally excellent Slicehost apparently had a network outage tonight, taking Booko down with them. They kept their blog, forums and twitter up-to-date which was appreciated. The outage, not so appreciated. When Booko came back up, naturally Fishpond was down, leading to some errors on Booko’s side. I’ve updated Booko to be more resiliant to 3rd party outages likke this and things are definitely improving.
In addition, I’ve added Melbourne University’s Bookstore to Booko – they sell both books and DVDs so it’s a great addition to have. This brings us to 32 stores searched for books and 7 for DVDs.
BookDepository fix
BookDepository added a clever feature recently to display the appropriate currency depending on your location. Unfortunately for Booko we’re hosted in the US and we started getting US pricing. Naturally the price was incorrect when Booko the converts USD into AUD assuming the original price is GBP. Fixed as of around 07:45 this morning.