It’s been great fun writing Booko in Ruby on Rails for lots of reasons, and the ORM module – ActiveRecord, is a big part of what makes it enjoyable. I know that ORMs exist in plenty of other languages, but RoR was my first exposure to it and it makes writing database backed applications much less tedious. But, as with all abstractions though, looking under the covers can help you solve problems and improve performance.
Booko has a “Most Viewed” section, which finds the products which have been viewed the most over the last 7 days. It does this by having a model called “View” which, as you might guess, records product views. The Product class asks the View class for the top 10 viewed products:
class Product < ActiveRecord::Base
...
def self.get_popular(period = 7.days.ago, count = 10 )
View.popular(period).collect {|v| v.product }.reverse.slice(0...count)
end
..
end
The View makes use of named scopes:
class View < ActiveRecord::Base
....
named_scope :popular, lambda { |time_ago| { :group => 'product_id',
:conditions => ['created_on > ?', time_ago],
:include => :product,
:order => 'count(*)' } }
...
end
class Product < ActiveRecord::Base
...
def self.get_popular(period = 7.days.ago, count = 10 )
View.popular(period).collect {|v| v.product }.reverse.slice(0...count)
end
...
end
The View makes use of named scopes:
class View < ActiveRecord::Base
....
named_scope :popular, lambda { |time_ago| { :group => 'product_id',
:conditions => ['created_on > ?', time_ago],
:include => :product,
:order => 'count(*)' } }
...
end
This all worked ok – but once the number of products being viewed started to grow into the 1000’s, this started taking longer and longer to generate the data for the view. At last count, it was running into the 50 second mark – way, way too long. The result of the calculation is cached for 30 minutes but that means that every 30 minutes, some poor user had to wait ~ 50seconds for the “Most Viewed” section to render. Time for a rethink.
There’s one obvious problem with the above method – all products viewed in the last 7 days are returned from the named_scope and instantiated and then count (by default, 10 ) number of Products are sliced off the result and are then displayed. Time to update the named scope so that it returns only the required number of products, and as a bonus, return them in the right order removing the need for the reverse method call.
class Product < ActiveRecord::Base
...
def self.get_popular(period = 7.days.ago, count = 10 )
View.popular(period, count).collect {|v| v.product }
end
...
end
class View < ActiveRecord::Base
....
named_scope :popular, lambda { |time_ago, freq| { :group => 'product_id',
:conditions => ['created_on > ?', time_ago],
:include => :product,
:order => 'count(*) desc',
:limit => freq } }
...
end
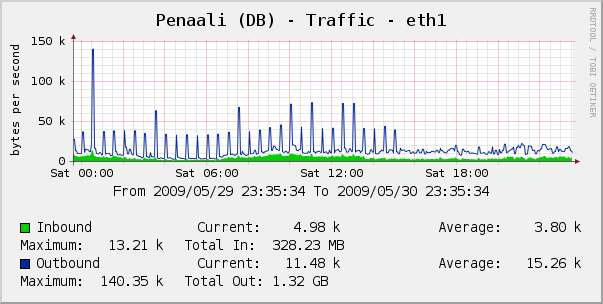
Updating the named_scope to return the required number of Products (in the right order), reduced the time from 56 seconds, to 6. In fact, subsequent calls returned in ~2 second mark no doubt due to some caching at the database side. Below is the graph showing network traffic to the database host. You can see periodic spikes, every 30 minutes, as the query ran and the database is hit for the 1000’s of Products to be instantiated. After the update, just after 15:00, the traffic becomes much steadier.
Moving that logic from the Ruby side to the database side resulted in a pretty substantial performance improvement.